
Dobrym ogólnym zarysem głównych gałęzi sztucznej inteligencji jest poniższy rysunek:
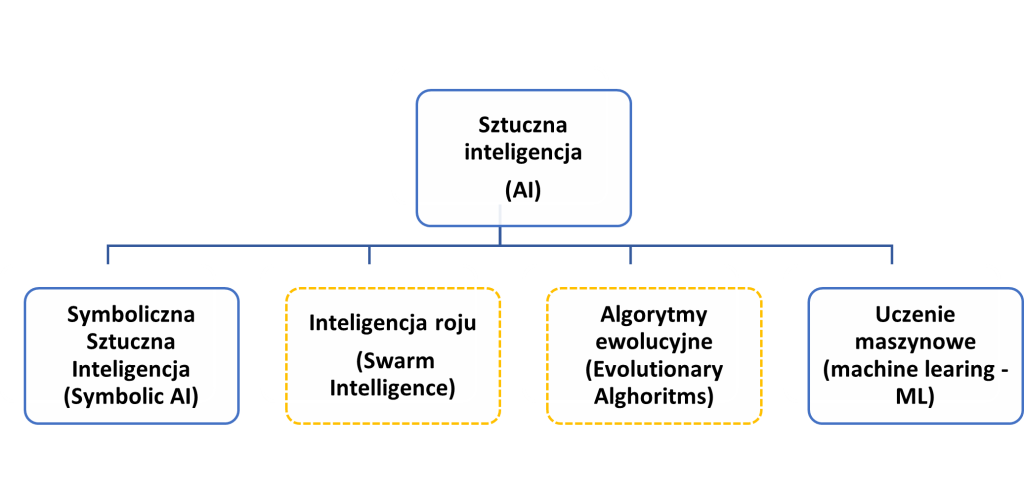
Rys. 1: Schemat przedstawiający główne gałęzie sztucznej inteligencji (AI), w tym metod uczenia maszynowego (Machine Learning ML) – opracowanie własne.
Generalnie wykres ten dzieli sztuczną inteligencję na gałęzie według kryterium zastosowanych metod i architektury, z których dwie nie budzą zasadniczych sporów (zaznaczone niebieską, ciągłą linią) a dwie (zaznaczone żółtą, przerywaną linią) są dyskusyjne i które, jak wskazano w poprzednim punkcie, zostaną pominięte.
Pierwsza z gałęzi, patrząc od lewej strony, historycznie najstarsza, to metody symboliczne, czasami zwane logicznymi, gdyż wykorzystują klasyczne metody logiki do przeprowadzania rozumowania. Zazwyczaj metody te wykorzystują wiedzę z uprzednio przygotowanych i na bieżąco aktualizowanych baz danych. Ich podział został przedstawiony na poniższym rysunku, gdzie wyróżniono poszczególne podgałęzie ze względu na różnice architektoniczne. Pomocniczym kryterium podziału są zastosowania poszczególnych rozwiązań.
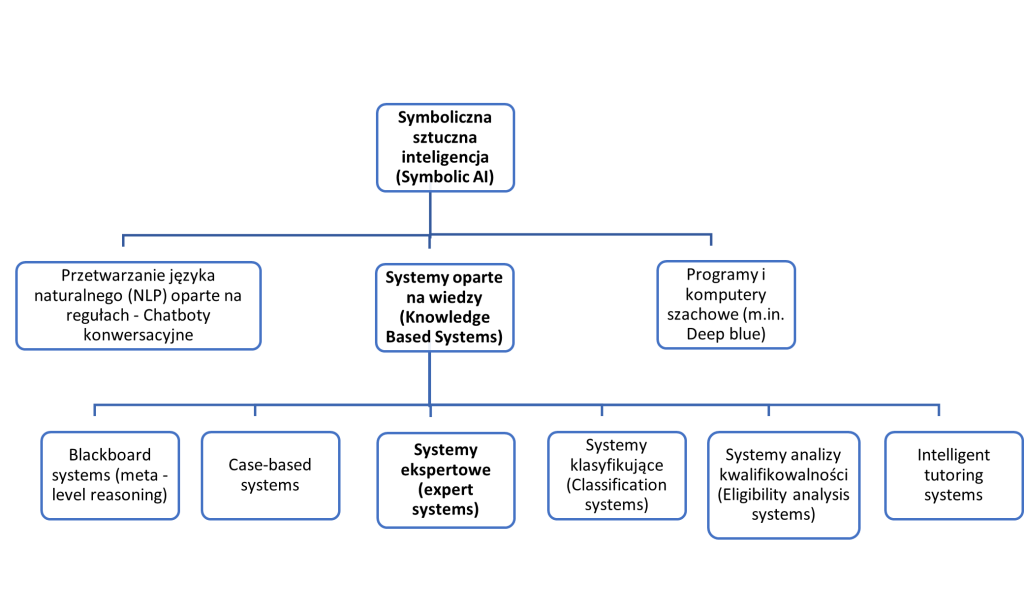
Rys. 2: Schemat przedstawiający gałęzie Symbolicznej sztucznej inteligencji (Symbolic AI), z wyróżnieniem najistotniejszej z nich – opracowanie własne.
W przypadku tych metod, analizowany przez dany system AI problem jest opisywany i zapisywany przy użyciu symboli, a algorytmy sztucznej inteligencji mają za zadanie tak przeanalizować ten zbiór symboli, by znaleźć i przedstawić rozwiązanie także w postaci symbolicznej. Najbardziej powszechnym i reprezentatywnym rodzajem metod symbolicznych są Systemy oparte na wiedzy (Knowledge – Based Systems – KBS), które składają się z bazy danych (zawierających wiedzę ogólną i zebraną od ekspertów wiedzę w danej dziedzinie) i „silnika wnioskującego” czyli programu, który zawiera zdefinowane reguły wnioskowań:
-
- jakimi posługują się specjaliści w danej dziedzinie (zazwyczaj heurystyczne) albo
-
- logicznymi czy matematycznymi.
Przykładem zadań, które jako pierwsze udało się z sukcesem rozwiązać korzystając z metod symbolicznych, były programy automatycznie dowodzące prawdziwości twierdzeń matematycznych, np. postawionych przez filozofa analitycznego i matematyka Bertranda Russela oraz grające w różne gry, w szczególności szachy[efn_note]R. Tadeusiewicz, Archipelag sztucznej inteligencji.
Część I, Napędy i Sterowanie, 2020/22/12, s. 24.
[/efn_note], czy system ekspertowy „Mycin” stworzony w 1972 r. na Uniwersytecie Stanford, służący do diagnostyki chorób krwi. Symboliczna sztuczna inteligencja może wykorzystywać metody wnioskowania oparte na regułach (rule – based) albo na heurystykach, które zostaną krótko i ogólnie scharakteryzowane w cz. „Metody całościowe”.
Spośród metod heurystycznych, a także rozwiązań AI w ogólności największą popularnością od 2016 r. cieszą się jednak rozwiązania określane zbiorczo jako uczenie maszynowe (Machine Learning – ML), których możliwości zostały w ciągu ostatnich 7 lat niezwykle rozwinięte. Według jednej z najczęściej cytowanych definicji uczenia maszynowego, autorstwa Toma Mitchella, „jest to obszar sztucznej inteligencji poświęcony algorytmom, które poprawiają się automatycznie poprzez doświadczenie[efn_note]Tom M. Mitchell, Machine Learning,
Redmond 1997, s. 2,[/efn_note]”. Definicja ta podkreśla rolę opartego na danych doświadczenia w procesie uczenia. Proces uczenia maszynowego składa się z kilku etapów, które poprzedza analiza danych albo środowiska. W przypadku przyjęcia metod wymagających przygotowania danych uczących (a tak jest najczęściej), do etapów tych należą: podział danych na zbiór treningowy i testowy, przy gotowanie (pre-processing) danych, przygotowanie modelu, strojenie modelu (wybór i optymalizacja hiperparametrów) oraz ocena jego działania na zbiorze treningowym i testowym przy pomocy tzw. metryk[efn_note]Za: T. Topór, Era uczenia maszynowego. Machine
learning w poszukiwaniu złóż ropy i gazu, Rynek Polskiej Nafty i Gazu 2021/16,
s. 22 – 23. Bardziej szczegółowo wyjaśnię te pojęcia, w zakresie potrzebnym do
uchwycenia ich znaczenia, w kolejnych częściach wprowadzenia.[/efn_note]. Najważniejsze gałęzie/modele uczenia maszynowego przedstawia rysunek nr 3, na którym wyróżniono sieci neuronowe, a w ich zbiorze wielkie modele językowe (LLM), oparte o tzw. „transformery”. Jest to podyktowane tym, że obecnie to te rozwiązania dysponują największymi możliwościami a z ich użyciem, także w stosowaniu prawa, wiążą się największe nadzieje.
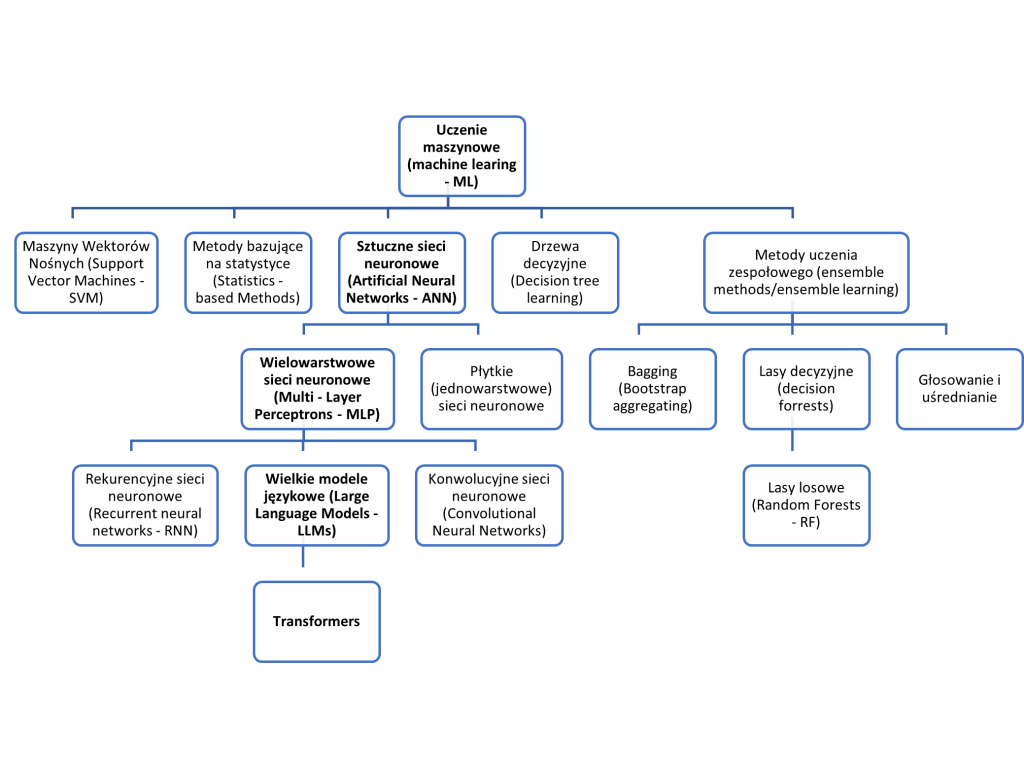
Rys. 3 Schemat przedstawiający główne gałęzie metod uczenia maszynowego (ML) z wyróżnieniem metod bazujących na głębokich sieciach neuronowych jako obecnie najbardziej zaawansowanych i najlepiej rokujących – opracowanie własne.
Każda ze zobrazowanych metod ma swoje wady i zalety. Przykładowo, konwolucyjne sieci neuronowe (CNN), znakomicie sprawdzają się przy rozpoznawaniu obrazów, ale gorzej w innych zadaniach. Wspomniane LLMy są znakomite w zadaniach wymagających streszczania i generowania tekstu, ale za cenę braku wyjaśnialności procesu, który doprowadził do powstania rozwiązania (tzw. problem czarnej skrzynki). Rekurencyjne sieci neuronowe z kolei w mniejszym stopniu obarczone tym ostatnim problemem, ale za to ich wydajność jest znacząco słabsza niż LLMów.
Niektóre z rozwiązań, prezentowanych na dwóch ostatnich rysunkach, zostaną bardziej szczegółowo omówione w kolejnych częściach „Wprowadzenia…”, ze względu na ich zastosowanie w wymiarze sprawiedliwości innych państw, w szczególności w procesie stosowania prawa albo dlatego, że ich potencjalne użycie w tej dziedzinie ma najlepsze rokowania.