
Wprowadzenie do zastosowania sztucznej inteligencji w wymiarze sprawiedliwości cz. I – kluczowe pojęcia
Jarosław Matuszczak – – sędzia Sądu Rejonowego w Malborku delegowany do pełnienia obowiązków głównego specjalisty w Wydziale Rozwoju Usług Sądowych Departamentu Informatyzacji i Rejestrów Sądowych Ministerstwa Sprawiedliwości
Niniejszy artykuł stanowi w znacznym stopniu wyciąg z rozdziału IV rozprawy doktorskiej pt.: „Wyrokowanie na posiedzeniu niejawnym w procesie cywilnym”, przygotowywanej przez autora, pod opieką naukową prof. dra hab. Tadeusza Wiśniewskiego, na Akademii Leona Koźmińskiego w Warszawie i ma, wobec zawartych tam treści, charakter wtórny. W szczególności zamieszczone w niniejszym artykule schematy hierarchiczne sztucznej inteligencji zostały przygotowane i w pierwszej kolejności zamieszczone w ww. projekcie rozprawy.
Czym jest sztuczna inteligencja?
Sztuczna inteligencja (ang. Artificial Intelligence – AI) może zostać ujęta jako zjawisko, będące przedmiotem badań naukowych i prac techniczno – rozwojowych, albo jako nauka zajmująca się badaniem inteligencji stworzonej przez człowieka. Czasem określa się tak poszczególne narzędzia czy rozwiązania, głównie techniczne w szczególności informatyczne, mogące wykonać pewne zadania, które dotychczas uważano za możliwe do zrealizowania jedynie przez ludzi.
Jedną z bardziej znanych definicją sztucznej inteligencji, rozumianej jako dziedzina nauki zaproponował John McCarthy, któremu przypisuje się stworzenie tego pojęcia w 1955 r. Według niego, sztuczna inteligencja jest dziedziną nauki i inżynierii, która zajmuje się tworzeniem inteligentnych maszyn, w szczególności inteligentnych programów komputerowych1.
Jeśli chodzi o AI ujętą jako zjawisko, w mojej ocenie, jedną z najlepszych definicji sztucznej inteligencji, głównie za sprawą jej pojemności, stworzyli Andreas Kaplan i Michael Haenlein, którzy określili tym mianem zdolność systemu do prawidłowego interpretowania danych pochodzących z zewnętrznych źródeł, nauki na ich podstawie oraz wykorzystywania tej wiedzy, do realizacji konkretnych zadań i celi poprzez elastyczne dostosowanie”[1].
W tym miejscu chciałbym zaznaczyć jedną istotną obserwację: sztuczna inteligencja rozumiana jako zjawisko, czy też narzędzie (system teleinformatyczny) tym różnić się będzie od „zwykłego” (obliczeniowego/logicznego) systemu komputerowego, że z założenia ma działać w warunkach niepewności, tj. w środowisku, w którym albo znamy równania (działania matematycznego) jakie ma nas doprowadzić do konkluzji, albo nie ma dostępu do wszystkich koniecznych danych, albo liczba danych, które mają wpływ na wynik, jest tak duża, że uwzględnienie ich wszystkich w obliczeniach, w czasie pozostałym do podjęcia decyzji, jest niemożliwe[2]. Jeśli bowiem mamy dostępne wszystkie niezbędne dane i wiemy, jakie wnioskowanie przeprowadzić (jakie równanie rozwiązać), nie mamy do czynienia z sztuczną inteligencją, tylko typowym programem dokonującym obliczeń. Innymi słowy, sztuczna inteligencja rozumiana w ten sposób ma na podstawie cząstkowej wiedzy dojść do wniosków zgodnych z rzeczywistością albo z oczekiwaniami twórcy czy użytkownika.
W przeciwieństwie do części autorów, nie uważam natomiast, by istotne i potrzebne, przy definiowaniu sztucznej inteligencji, było odwołanie się do (rzekomego) jej podobieństwa do inteligencji ludzkiej, zwłaszcza, że bezwiednie kieruje to uwagę na kwestię osobowości[3], co niepotrzebnie zakłóca opis tego zjawiska.
Definicje legalne sztucznej inteligencji
Obecnie w polskim porządku prawnym brak jest definicji legalnej sztucznej inteligencji, choć może się to wkrótce zmienić za sprawą dwóch aktów prawnych o charakterze ponadnarodowym.
Pierwszym z nich jest projektowane Rozporządzenie Parlamentu Europejskiego i Rady ustanawiające zharmonizowane przepisy dotyczące sztucznej inteligencji (akt w sprawie sztucznej inteligencji) i zmieniające niektóre akty ustawodawcze unii. Zgodnie z jego projektowanym art. 3 ust. 1 pkt 1, system sztucznej inteligencji oznacza oprogramowanie opracowane przy użyciu co najmniej jednej spośród technik i podejść wymienionych w załączniku I, które może – dla danego zestawu celów określonych przez człowieka – generować wyniki, takie jak treści, przewidywania, zalecenia lub decyzje wpływające na środowiska, z którymi wchodzi w interakcję[1].
Drugim jest projekt Konwencji Rady Europy – „Revised Zero Draft [framework] Convention on artificial intelligence, human rights, democracy and the rule of law”, który w art. 2 lit. a przewiduje, następującą definicję: „system sztucznej inteligencji” oznacza dowolny system algorytmiczny lub kombinację takich systemów, które zgodnie z definicją zawartą w niniejszej konwencji oraz w prawie krajowym każdej ze Stron wykorzystują metody obliczeniowe wywodzące się ze statystyki lub innych technik matematycznych do wykonywania funkcji, które są powszechnie kojarzone z ludzką inteligencją lub które w innym przypadku wymagałyby ludzkiej inteligencji, i które wspomagają lub zastępują osąd ludzkich decydentów w wykonywaniu tych funkcji. Funkcje takie obejmują, ale nie ograniczają się do, przewidywania, planowania, klasyfikacji, rozpoznawania wzorców, organizacji, percepcji, rozpoznawania mowy/dźwięku/obrazu, generowania tekstu/dźwięku/obrazu, tłumaczenia językowego, komunikacji, uczenia się, reprezentacji i rozwiązywania problemów[2].
Odnośnie tych dwóch projektów aktów prawnych, zauważyć należy, że wyraźnie odnoszą się do sztucznej inteligencji rozumianej jako pewne narzędzie czy też rozwiązanie o charakterze technicznym – informatycznym. Wynika z użycia słowa „system” w definiowanym pojęciu oraz słów „oprogramowanie” (w projekcie Rozporządzenia AIA) i „system algorytmiczny lub kombinację takich systemów” (w projekcie Konwencji Rady Europy), w wyrażeniu, za pomocą którego określono wyraz definiowany. Definicje te zasadniczo pomijają rozwiązania AI, koncentrujące się na optymalizacji procesów decyzyjnych i wspieraniu argumentacji, takie jak np. inteligencja roju, czy na wytwarzaniu nowych metod i rozwiązań AI w sposób wzorowany na mechanizmie ewolucji organizmów żywych (algorytmy ewolucyjne). Spornym jest także wśród naukowców to, czy w ogóle należy je zaliczać do sztucznej inteligencji. Ich istnienie w niniejszym artykule zostanie odnotowane, jednakże ze względu na ich prawdopodobnie relatywnie niewielki wpływ na kluczowe czynności dla sprawowania wymiaru sprawiedliwości nie będą omawiane.
Sztuczna inteligencja – rodzaje i kluczowe pojęcia
Główne gałęzie sztucznej inteligencji
Dobrym ogólnym zarysem głównych gałęzi sztucznej inteligencji jest poniższy rysunek:
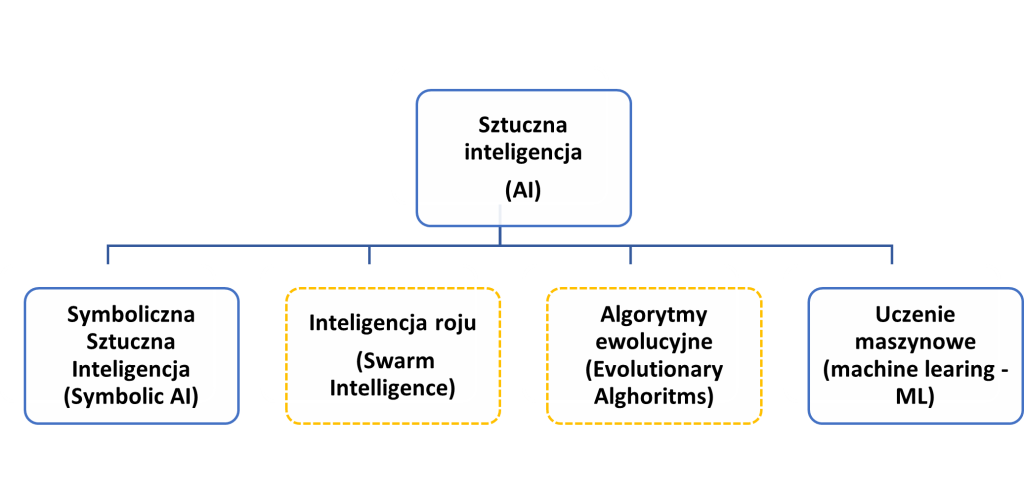
Rys. 1: Schemat przedstawiający główne gałęzie sztucznej inteligencji (AI), w tym metod uczenia maszynowego (Machine Learning ML) – opracowanie własne.
Generalnie wykres ten dzieli sztuczną inteligencję na gałęzie według kryterium zastosowanych metod i architektury, z których dwie nie budzą zasadniczych sporów (zaznaczone niebieską, ciągłą linią) a dwie (zaznaczone żółtą, przerywaną linią) są dyskusyjne i które, jak wskazano w poprzednim punkcie, zostaną pominięte.
Metody symboliczne
Pierwsza z gałęzi, patrząc od lewej strony, historycznie najstarsza, to metody symboliczne, czasami zwane logicznymi, gdyż wykorzystują klasyczne metody logiki do przeprowadzania rozumowania. Zazwyczaj metody te wykorzystują wiedzę z uprzednio przygotowanych i na bieżąco aktualizowanych baz danych. Ich podział został przedstawiony na poniższym rysunku, gdzie wyróżniono poszczególne podgałęzie ze względu na różnice architektoniczne. Pomocniczym kryterium podziału są zastosowania poszczególnych rozwiązań.
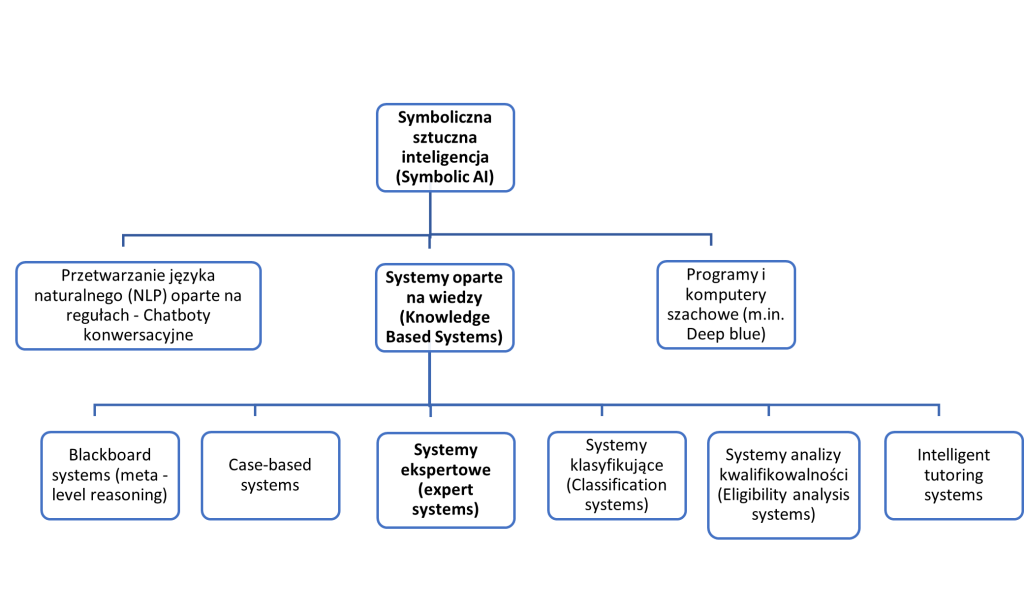
Rys. 2: Schemat przedstawiający gałęzie Symbolicznej sztucznej inteligencji (Symbolic AI), z wyróżnieniem najistotniejszej z nich – opracowanie własne.
W przypadku tych metod, analizowany przez dany system AI problem jest opisywany i zapisywany przy użyciu symboli, a algorytmy sztucznej inteligencji mają za zadanie tak przeanalizować ten zbiór symboli, by znaleźć i przedstawić rozwiązanie także w postaci symbolicznej. Najbardziej powszechnym i reprezentatywnym rodzajem metod symbolicznych są Systemy oparte na wiedzy (Knowledge – Based Systems – KBS), które składają się z bazy danych (zawierających wiedzę ogólną i zebraną od ekspertów wiedzę w danej dziedzinie) i „silnika wnioskującego” czyli programu, który zawiera zdefinowane reguły wnioskowań:
- jakimi posługują się specjaliści w danej dziedzinie (zazwyczaj heurystyczne) albo
- logicznymi czy matematycznymi.
Przykładem zadań, które jako pierwsze udało się z sukcesem rozwiązać korzystając z metod symbolicznych, były programy automatycznie dowodzące prawdziwości twierdzeń matematycznych, np. postawionych przez filozofa analitycznego i matematyka Bertranda Russela oraz grające w różne gry, w szczególności szachy[1], czy system ekspertowy „Mycin” stworzony w 1972 r. na Uniwersytecie Stanford, służący do diagnostyki chorób krwi. Symboliczna sztuczna inteligencja może wykorzystywać metody wnioskowania oparte na regułach (rule – based) albo na heurystykach, które zostaną krótko i ogólnie scharakteryzowane w cz. „Metody całościowe”.
KBS a system ekspertowy
W tym miejscu wyjaśnienia wymaga różnica pomiędzy systemami opartymi na wiedzy (KBS) a systemami ekspertowymi. Spotkać się można z zamiennym stosowaniem tych pojęć, co wyjaśnia się w ten sposób, że mówiąc o KBSach ma się na myśli bardziej architekturę danego systemu, a o systemach eksperckich – uwagę zwraca się na przedmiot ich zastosowania (ma zastąpić pracę eksperta w danej dziedzinie[1]. Zasadniczo jednak przyjmuje się (i tak też tu czynię), że system ekspercki jest specyficznym rodzajem KBS, który został zaprojektowany do wykonywania zadań, które normalnie wymagałyby specjalistycznej wiedzy ludzkiego eksperta. Zatem podstawową ideą systemu ekspertowego jest przeniesienie wiedzy eksperta przez tzw. inżyniera wiedzy (wyspecjalizowanego programistę) do systemu informatycznego, który zostaje wyposażony w bazę wiedzy stanowiącą połączenie wiedzy ogólnej i wiedzy eksperta[2]. Tym samym główną różnicą między nimi jest to, że KBS może być używany do każdego zadania, które wymaga korzystania z wiedzy zebranej w danej dziedzinie, podczas gdy system ekspercki jest specjalnie zaprojektowany do wykonywania zadań wymagających wiedzy na poziomie eksperta. Zazwyczaj systemy eksperckie mają charakter doradczy (prezentują rozwiązania dla użytkownika, który jest w stanie ocenić ich jakość – człowiek może przyjąć rozwiązanie oferowane przez system lub je odrzucić i zażądać innego rozwiązania). Istnieją jednak systemy ekspertowe o charakterze decyzyjnym (podejmujące decyzje bez kontroli człowieka, zazwyczaj w sytuacjach, gdzie udział człowieka jest utrudniony lub niemożliwy, krytykujące (wyszukujące luk w rozumowaniu)[3]. Systemy ekspertowe, jako pierwsze spośród rozwiązań mieszczących się w zbiorze sztucznej inteligencji znalazły szerokie zastosowanie praktyczne. Próbowano je także zastosować w procesie stosowania prawa, choć z gorszymi rezultatami niż w innych dziedzinach[1]. Systemy ekspertowe w swojej naturze są systemami informatycznymi przeznaczonymi do rozwiązywania specjalistycznych problemów wymagających profesjonalnej ekspertyzy opartej na wiedzy, a zatem są związane z jej pozyskiwaniem i przetwarzaniem. Ich starsze wersje posługiwały się metodami wnioskowania opartymi na sztywnych regułach, ale w nowszych wykorzystano już metody całościowe.
Metody całościowe
Metody całościowe, różnią się od metod wnioskowań opartych na regułach, że bazują na algorytmach heurystycznych, tj. albo wprost na rachunku prawdopodobieństwa albo na metodach heurystycznych, które mieszczą się we wspomnianym wyżej rachunku symbolicznym (np. logika rozmyta). Termin „heurystyka” jest często używany w dziedzinie sztucznej inteligencji dla określenia metod, które – w odróżnieniu od dokładnych algorytmów obliczeniowych – polegają na poszukiwaniu rozwiązania w drodze swoistego „zgadywania”. Algorytmy heurystyczne znalazły swoje zastosowanie ze względu na występowanie tzw. bariery złożoności obliczeniowej, która powoduje, że czas potrzebny na ustalenie wyniku w drodze dokładnych obliczeń, przeprowadzanych przez współczesne komputery klasyczne, będzie zbyt długi, by wynik mógł być przydatny. Są to zatem metody pozwalające ustalić wynik, np. odnaleźć rozwiązanie problemu w przybliżeniu, poprzez oszacowania (określenia w przybliżeniu) gdzie się znajduje. Owa swoistość polega na tym, że odbywa się według pewnych założeń albo metod, w szczególności wynikających z rachunku prawdopodobieństwa, wspomnianej logiki rozmytej, metod wynikających z doświadczeń ekspertów, czy z zachowań stadnych zwierząt (w przypadku tzw. inteligencji roju). Heurystyki działają bez gwarancji, że uda się znaleźć rozwiązanie, a gdy je znajdą, to bez pewności, że jest to rozwiązanie optymalne. Stosuje się je jednak ze względu na ograniczenie dostępnych zasobów, w tym przypadku wspomnianej mocy obliczeniowej klasycznych komputerów: heurystyki są bardzo sprawne obliczeniowo, więc dla bardzo złożonych problemów (a takie z reguły pojawiają się w zastosowaniach sztucznej inteligencji) można znaleźć rozwiązanie w akceptowalnym czasie, do czego algorytm oparty na regułach nie jest zdolny
Machine Learning –popularność wynikająca ze skuteczności
Spośród metod heurystycznych, a także rozwiązań AI w ogólności największą popularnością od 2016 r. cieszą się jednak rozwiązania określane zbiorczo jako uczenie maszynowe (Machine Learning – ML), których możliwości zostały w ciągu ostatnich 7 lat niezwykle rozwinięte. Według jednej z najczęściej cytowanych definicji uczenia maszynowego, autorstwa Toma Mitchella, „jest to obszar sztucznej inteligencji poświęcony algorytmom, które poprawiają się automatycznie poprzez doświadczenie”[1]. Definicja ta podkreśla rolę opartego na danych doświadczenia w procesie uczenia. Proces uczenia maszynowego składa się z kilku etapów, które poprzedza analiza danych albo środowiska. W przypadku przyjęcia metod wymagających przygotowania danych uczących (a tak jest najczęściej), do etapów tych należą: podział danych na zbiór treningowy i testowy, przy gotowanie (pre-processing) danych, przygotowanie modelu, strojenie modelu (wybór i optymalizacja hiperparametrów) oraz ocena jego działania na zbiorze treningowym i testowym przy pomocy tzw. metryk[2]. Najważniejsze gałęzie/modele uczenia maszynowego przedstawia rysunek nr 3, na którym wyróżniono sieci neuronowe, a w ich zbiorze wielkie modele językowe (LLM), oparte o tzw. „transformery”. Jest to podyktowane tym, że obecnie to te rozwiązania dysponują największymi możliwościami a z ich użyciem, także w stosowaniu prawa, wiążą się największe nadzieje.
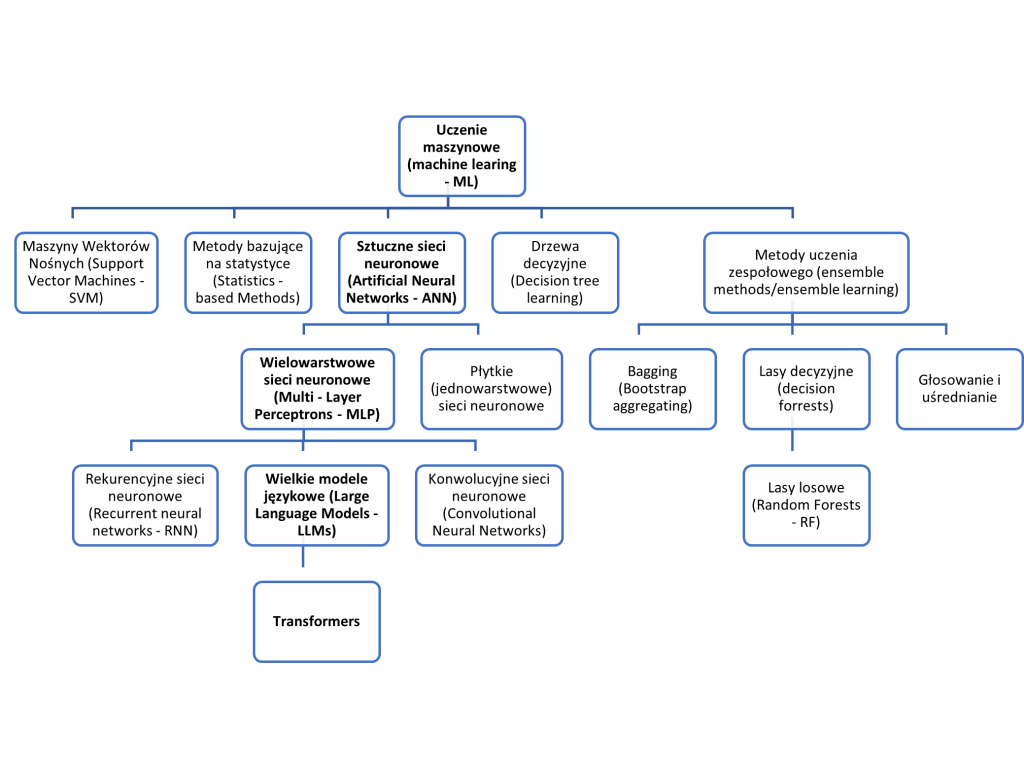
Rys. 3 Schemat przedstawiający główne gałęzie metod uczenia maszynowego (ML) z wyróżnieniem metod bazujących na głębokich sieciach neuronowych jako obecnie najbardziej zaawansowanych i najlepiej rokujących – opracowanie własne.
Każda ze zobrazowanych metod ma swoje wady i zalety. Przykładowo, konwolucyjne sieci neuronowe (CNN), znakomicie sprawdzają się przy rozpoznawaniu obrazów, ale gorzej w innych zadaniach. Wspomniane LLMy są znakomite w zadaniach wymagających streszczania i generowania tekstu, ale za cenę braku wyjaśnialności procesu, który doprowadził do powstania rozwiązania (tzw. problem czarnej skrzynki). Rekurencyjne sieci neuronowe z kolei w mniejszym stopniu obarczone tym ostatnim problemem, ale za to ich wydajność jest znacząco słabsza niż LLMów.
Niektóre z rozwiązań, prezentowanych na dwóch ostatnich rysunkach, zostaną bardziej szczegółowo omówione w kolejnych częściach „Wprowadzenia…”, ze względu na ich zastosowanie w wymiarze sprawiedliwości innych państw, w szczególności w procesie stosowania prawa albo dlatego, że ich potencjalne użycie w tej dziedzinie ma najlepsze rokowania.
W jaki sposób przebiega proces uczenia maszynowego?
W przypadku metod czy też modeli uczenia maszynowego, istotne jest także to, w jaki sposób następuje owo uczenie. Zasadniczo wyróżnia się trzy, czasem cztery, główne metody, które, co do zasady, są niezależne od tego, które z rozwiązań architektonicznych, zaprezentowanych na powyższym schemacie, zostanie wybrane. Samo uczenie maszynowe zawsze następuje na zbiorach danych, choć czasem są one budowane na danych pozyskiwanych samodzielnie przez model. Zbiory danych mogą zostać wcześniej dokładnie opisane (zaetykietowanie) przez człowieka. Oznacza to, że każdy obiekt (obraz, dźwięk, symbol, fraza/zdanie) w bazie danych został opisany według różnych kryteriów przez osoby etykietujące. Im więcej etykiet, tym, co do zasady, lepszy zbiór uczący. Zbiory danych mogą być także pozbawione etykiet i być albo pozbawione jakiejkolwiek klasyfikacji czy filtracji albo poddane ogólnej selekcji danych, polegającej na np. usunięciu zbyt dużych obrazów albo fraz zawierających określone, niechciane słowa. W przypadku uczenia maszynowego źródło (ewentualnie środowisko pozyskiwania) i rozmiar zbioru danych, ich wybór, filtrowanie i zaetykietowanie (w tym sposób etykietowania) mają kluczowe znaczenie dla skuteczności danego modelu. Zasadą jest, że im lepsze są dane wejściowe (im lepiej przygotowane środowisko), tym lepsze są rezultaty (dane wyjściowe) i tym mniejszy (tańszy, mający prostszą budowę/mniejszą liczbę parametrów) model uczenia maszynowego może zostać zastosowany.
Uczenie nadzorowane
Jest to sposób uczenia, w którym zbiór danych na których model ML się uczy (zbiór danych treningowych), zawiera tzw. etykiety albo klasy. Model ML ustala, na podstawie etykiet, przesłanki stojące u podstaw określonych wniosków, ale w sposób statystyczny a nie logiczny. Inaczej mówiąc ustala jakimi cechami musi dysponować dany obiekt, by zaliczyć go do danej klasy (np. jakie cechy muszą wystąpić na zdjęciu, by uznać, że przedstawia ono kota, albo by osiągnąć określoną wartość (np. by ustalić wartość pojazdu system uczy się na podstawie etykiet wiążących ze sobą markę i model pojazdu, jego wiek, liczbę właścicieli, etc.). Następnie na podstawie tego, czego model nauczył się na zaetykietowanym zbiorze danych, próbuje dokonywać takich ustaleń na zbiorze danych, nie posiadającym etykiet (np. na zdjęciach zwierząt w internecie).
Uczenie nadzorowane
W przypadku tego sposobu uczenia, obiekty w zbiorze danych treningowych nie mają nadanych etykiet ani nie mają przypisanego poprawnego wyniku. Zadanie jakie wykonuje uczący się model ML w tym przypadku polega na ustaleniu struktury danych albo znalezieniu, zazwyczaj wcześniej nieznanych, wzorów (powiązań między danymi) pozwalających przewiedzieć pewne skutki. Przykładowo, model ML może pogrupować podobne (dla niego) elementy w „podzbiory” albo wychwycić niedostrzegalne dla człowieka przesłanki określonego postępowania konsumentów czy wyborców.
Uczenie przez wzmacnianie
W przeciwieństwie do wymienionych powyżej metod uczenia, uczenie to nie wymaga przygotowania zbioru danych treningowych. W tym przypadku model ML jest umieszczany w przygotowanym wcześniej środowisku/otoczeniu, z którego sam, automatycznie zbiera dane, a następnie przedstawia rozwiązania, za które otrzymuje wzmocnienie pozytywne (nagroda) albo negatywne (kara). Celem do którego dąży model uczony w ten sposób, jest zmaksymalizowanie liczby rozwiązań „nagradzanych”. Zazwyczaj model działa w środowisku, w którym informacja zwrotna na temat prawidłowych albo błędnych wyborów jest uzyskiwana z pewnym opóźnieniem, np. w grach, zwłaszcza w tych w których rezultat może zostać ustalony dopiero pod koniec gry, jak np. gra w GO.
Uczenie samonadzorowane
Jest to proces uczenia maszynowego, znany także jako uczenie predykcyjne lub pretekstowe, w którym model sam uczy się części danych wejściowych na podstawie innej części danych wejściowych. Często jest uznawany za rodzaj (podzbiór) uczenia nienadzorowanego. W tym procesie dane nie mające jakichkolwiek etykiet (jak w przypadku uczenia nienadzorowanego) są przekształcane bez udziału człowieka w dane posiadające etykiety (jak przy uczeniu nadzorowanym), poprzez automatyczne nadawanie im, przez uczony model, etykiet (czasami zwanych pseudoetykietami). Upraszczając mocno ten proces, można go opisać w ten sposób, że w budowanej przez model bazie danych, umieszcza blisko siebie próbki (a w zasadzie tzw. osadzenia – embeddings) zdaniem modelu podobne (np. ze względu na strukturę danych, statystycznie występujące związki itd.), jednocześnie próbując umieścić dalej od nich osadzenia pochodzące z odmiennych właściwościami próbek. Proces ten zmierza do zidentyfikowania ukrytej części danych wejściowych z dowolnej nieukrytej części danych wejściowych. Innymi słowy, w toku uczenia model usiłuje odgadnąć, np. koniec zdania na podstawie początku, początek zdania na podstawie jego końca, górę obrazu na podstawie dołu, itd., samodzielnie weryfikując trafność odpowiedzi i na tej podstawie etykietując słowa jako blisko albo daleko powiązane. W rezultacie powstaje baza danych z nadanymi etykietami. Na jej podstawie, w modelu służącym do przetwarzaniu języka naturalnego, na podstawie kilku znanych słów rozpoczynających zdanie, czy akapit, ten sam albo inny model może uzupełnić jego resztę, używając bazy danych powstałej w toku uczenia samonadzorowanego. Robi to dzięki wcześniej automatycznie nadanym etykietom, które pozwalają na odnalezienie związków między słowami. Zazwyczaj uczenie samonadzorowane wykorzystuje ogromne bazy danych bez etykiet (np. wszystkich opublikowanych dzieł literackich w języku polskim)[1]. Różnica pomiędzy tym modelem uczenia a uczeniem nienadzorowanym polega na tym, że uczenie samonadzorowane skoncentrowane jest przede wszystkim na stworzeniu bazy danych z etykietami (którą potem można wykorzystać do wstępnego trenowania innego modelu) a nie na samym modelu, a uczenie nienadzorowane na stworzeniu właśnie tegoż modelu, w związku z czym w jego toku nie następuje nadanie etykiet danym.
Powyższe kategorie uczenia nie mają charakteru rozłącznego. Dany model może być uczony za pomocą ich połączenia. Na przykład tzw. uczenie półnadzorowane jest oparte częściowo o uczenie nadzorowane i częściowo o uczenie nienadzorowane. Może to polegać na tym, że najpierw zastosowany zostanie schemat uczenia nienadzorowanego do wstępnego treningu modelu (np. trening na ogromnej ilości pozbawionych etykiet dokumentów urzędowych i sądowych pobranych z systemów repretoryjno – biurowych), który następnie będzie „dostrajany” do zadania, jakie ma zasadniczo wykonywać. To „dostrojenie” (ang. finetuning) nastąpi poprzez uczenie nadzorowane na danych zaetykietowanych, dotyczących dziedziny w której model ma być stosowany (np. na precyzyjnie opisanych i pogrupowanych rodzajami spraw uzasadnieniach orzeczeń sądowych)
Inne ważne pojęcia w dziedzinie sztucznej inteligencji
Oprócz rozróżnienia ww. podstawowych gałęzi sztucznej inteligencji oraz metod uczenia części z nich, istotna, dla orientacji w tej dziedzinie, jest znajomość trzech poniższych pojęć:
Algorytm
Ścisły przepis postępowania, którego przestrzeganie gwarantuje otrzymanie danych wynikowych z dostarczonych danych wejściowych, w skończonym czasie, zgodnie ze specyfikacją użytkową danego problemu. Algorytm stanowi ogólny schemat i może być zapisywany w różnych językach i konwencjach[1]. Algorytm może być wyrażony w języku naturalnym (jego odmianą jest język prawniczy), języku graficznym (schemat), arkuszu kalkulacyjnym albo w języku programowania.
Język programowania
Narzędzie do formułowania programów dla komputerów; jest językiem formalnym, którego składnia określa zasady zapisu programów (w sposób jednoznaczny i łatwy do analizy), a semantyka przypisuje programom ich interpretację (określa efekty działania programu zapisanego w języku programowania)[1]. Inaczej: standardowy środek dokumentowania algorytmów w sposób umożliwiający komputerowi ich wykonanie.
Kod źródłowy
Jest to algorytm wyrażony w danym języku programowania. Inaczej: jest to ciąg poleceń zapisany w postaci programu źródłowego czyli właśnie kod źródłowy, który nadaje się do wykonania przez automat, w szczególności przez komputer[1].
c.d.n.
- sdsad ↩︎